


(artykuł stanowi kontynuację tekstu „Kod zgodnie z zasadami sztuki”)
Zarządzanie zadaniami, sprawami otwartymi i zmianami
Metodyka Rozwoju Oprogramowania BCC (aktualnie All for One Poland) wymaga, aby każdy projekt rozwoju oprogramowania prowadził rejestry:
- zadań,
- spraw otwartych,
- zmian zakresu.
Zadania – wynikają ze specyfikacji wymagań i planu projektu. Są przypisane do pojedynczych osób odpowiedzialnych za ich wykonanie (najczęściej programistów). Rejestr ten pozwala oceniać ogólny wolumen prac wynikających z zakresu projektu.
Sprawy otwarte – podczas gdy zadania wynikają z pierwotnego planu projektu, sprawy otwarte to lista wszystkich „niespodzianek” lub wątpliwości, które pojawiły się w trakcie realizacji. Szczególnie istotną kategorią spraw otwartych są błędy zidentyfikowane podczas testów rozwiązania. Sprawy otwarte zostają przypisane do pojedynczych osób odpowiedzialnych za ich rozwiązanie i następnie śledzimy ich status. Lista spraw otwartych określa dodatkowy wolumen prac niewynikających wprost z zakresu projektu, lecz wymaganych do realizacji w celu jego pomyślnego ukończenia (doświadczony kierownik projektu zakłada na nie bufor w harmonogramie, np. na błędy do poprawienia po testach).
Zmiany zakresu – to szczególny podzbiór zadań, które pojawiają się w trakcie projektu i wynikają z modyfikacji wymagań, opisanych w koncepcji. Wymagania mogą się zmieniać w wyniku zmian w otoczeniu projektu (np. dział marketingu firmy opracował nowe założenia kampanii promocyjnej i należy wprowadzić nowy algorytm rabatów w module kalkulacji cen). Mogą również zmieniać się w efekcie lepszego zrozumienia potrzeb biznesowych przez właściciela produktu (np. po testach prototypu rozwiązania). Wydzielenie zmian zakresu do osobnej kategorii jest najbardziej istotne w przypadku projektów realizowanych dla klienta zewnętrznego i w modelu fix-price, ponieważ zadania kwalifikowane do tej grupy wpływają na rozliczanie kosztów projektu.
Kierownik projektu ustala w fazie przygotowania projektu rozwiązania techniczne dla prowadzenia ww. rejestrów (np. lista w portalu SharePoint, Lotus Notes lub All for One ECM) oraz komunikuje wszystkim uczestnikom projektu procedury z nimi związane.
W praktyce rejestr zadań, spraw otwartych i zmian zakresu może być prowadzony jako pojedyncza baza danych, pod warunkiem że każdy typ można łatwo zidentyfikować i odseparować (np. filtry lub różne widoki list w portalu projektowym). Zebranie tego typu danych w jednej bazie ułatwia przenoszenie pozycji pomiędzy rejestrami (np. temat zakwalifikowany początkowo jako błąd z testów po głębszej analizie okazuje się zmianą zakresu).
Standard zarządzania sprawami otwartymi
W dużym projekcie najliczniejsza i najbardziej „zmienna” grupa pozycji to lista spraw otwartych. Podczas gdy zadania projektowe planujemy w rytmie tygodni lub miesięcy, sprawy otwarte mogą pojawiać się podczas testów rozwiązania lub po starcie produkcyjnym w tempie kilku na godzinę, a oczekiwane terminy ich rozwiązania są liczone w pojedynczych dniach lub godzinach.
Rekomendowane praktyki zarządzania rejestrem spraw otwartych:
- inicjatorem zgłoszenia może być dowolny uczestnik projektu – nawet jeśli w projekcie została formalnie wyodrębniona rola testera, to nic nie stoi na przeszkodzie, żeby zgłoszenia spraw otwartych/błędów rejestrowali również programiści, kierownik projektu lub właściciel produktu. Jest w interesie projektu, żeby lista spraw otwartych zawierała wszystkie zidentyfikowane problemy, ponieważ uczestnicy projektu otrzymują realny obraz sytuacji i mogą lepiej prognozować czas pozostający do ukończenia prac;
- sprawy otwarte muszą mieć ustaloną jasną sekwencję statusów, zakomunikowaną przez kierownika projektu wszystkim uczestnikom i jednakowo interpretowaną przez wszystkich (typowy przykład nieporozumień: status „problem poprawiony” – czy oznacza to, że programista poprawił błąd tylko w swoim lokalnym środowisku rozwojowym, czy przeniósł rozwiązanie na system testowy, czy jest ono już zatwierdzone i przeniesione na system produkcyjny?);
- sekwencja statusów spraw otwartych powinna być dobrze dostosowana do środowiska projektowego; przykładowo jeśli każda zmiana kodu przechodzi przez system testowy i trafia na koniec do systemu produkcyjnego, to definiujemy oddzielne statusy „gotowe do przeniesienia do systemu QA” i „gotowe do przeniesienia na system PRD”; w przeciwnym razie nie będziemy mogli odpowiedzieć jednoznacznie na kluczowe pytanie: „w którym systemie jest dostępne rozwiązanie danego problemu do testów?”;
- zazwyczaj definiujemy status „nowy”, w którym inicjator zgłoszenia zakłada każdą sprawę otwartą, a dopiero programista wiodący lub kierownik projektu zmienia status na „przypisany”, po przydzieleniu osoby odpowiedzialnej za rozwiązanie danego zgłoszenia;
- osobą zamykającą zgłoszenie może być tylko jego inicjator – programista udostępnia rozwiązanie do testów, lecz ostateczna ocena, czy jest ono zgodne z oczekiwaniami, należy do osoby, która utworzyła zgłoszenie.
Praktyczne jest ponumerowanie poszczególnych statusów w ich logicznej sekwencji – ułatwia to późniejsze grupowanie i sortowanie listy statusów w rejestrze, według stanu zaawansowania prac.
Na schemacie prezentujemy przykładowy zestaw statusów dla listy spraw otwartych.
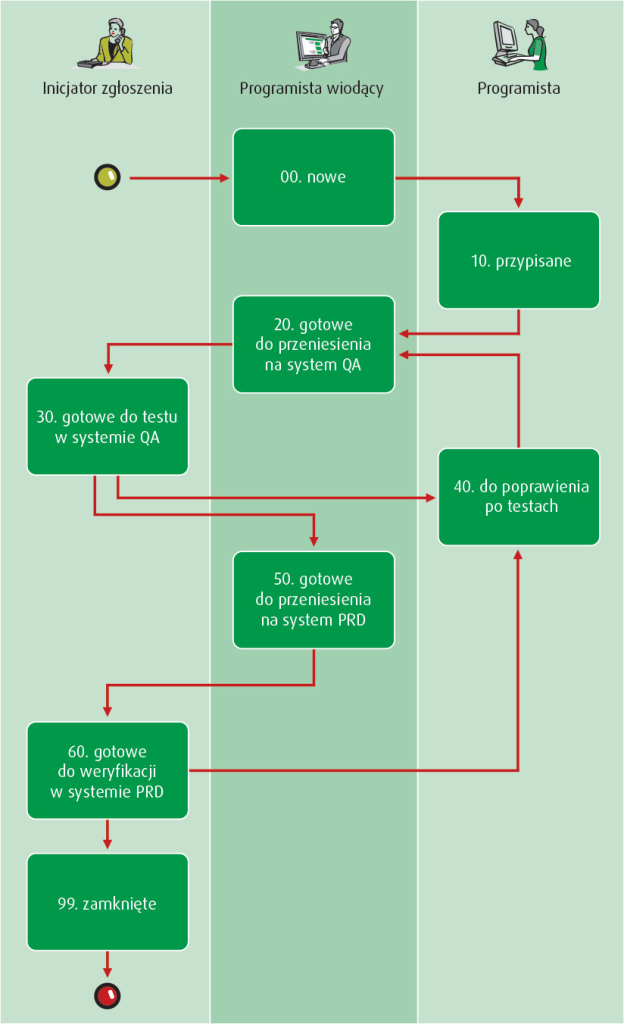
Zestaw statusów dla listy spraw otwartych (przykład). W kolumnach zaznaczono role projektowe, które obsługują zgłoszenia w danym statusie
Zapewnienie jakości
Zapewnienie jakości (ang. quality assurance, QA) to systematyczne działania, które weryfikują zgodność produktu z wymaganiami. Najczęściej pierwszym skojarzeniem z QA są testy gotowego rozwiązania, lecz metodyka rozwoju oprogramowania powinna również promować inne techniki, stosowane na wcześniejszych etapach produkcji nowego systemu (usuwanie błędów na wcześniejszych etapach jest tańsze: łatwiej poprawić specyfikację niż działający system, łatwiej poprawić jeden moduł systemu niż zintegrowaną całość itd.).
Zapewnienie jakości ma ogromne znaczenie dla skutecznego planowania i prognozowania harmonogramu projektu. Błędy dostrzeżone w rozwiązaniu należy usuwać z wysokim priorytetem, zanim przejdziemy do implementacji kolejnych wymagań funkcjonalnych. Czas implementacji pojedynczego wymagania można przewidywać dość precyzyjnie. Natomiast czas poprawiania błędów jest większą niewiadomą: w momencie zarejestrowania błędu nie wiemy jeszcze, czy do jego zamknięcia wystarczy trywialna poprawka kilku linii kodu na godzinę pracy, czy potrzebna będzie mozolna analiza, przygotowanie wielu próbek danych testowych i trwająca tydzień przebudowa interfejsu…
Jest to więc jedno z ważniejszych zadań kierownika projektu, aby obok naturalnej tendencji do „dostarczania” nowych funkcji, stale dbać o wysoką jakość istniejącej bazy kodu i priorytetyzować rozwiązywanie znanych błędów. Jeśli zostanie to zaniedbane, to harmonogram przyszłych postępów prac będzie obarczony coraz większą niepewnością, ponieważ dodajemy nowe funkcje do systemu, który nie ma solidnych „fundamentów”.
Przeglądy i formalne zatwierdzenie specyfikacji
Specyfikację wymagań funkcjonalnych dostarcza odpowiedzialny właściciel produktu. Nie oznacza to jednak, że przerzucamy gotową specyfikację na drugą stronę „muru” oddzielającego klienta i zespół projektowy, do bezwarunkowej realizacji.
Zespół programistów lub programista wiodący powinien przeanalizować specyfikację pod kątem jej przejrzystości i kompletności. Dopiero po wyjaśnieniu wszystkich wątpliwości i uzupełnieniu lub skorygowaniu koncepcji przystępujemy do realizacji prac na jej podstawie.
Przegląd specyfikacji przez osoby odpowiedzialne za jej realizację należy zaplanować w każdym przypadku, natomiast znaczenie formalnego zatwierdzania zależy od sposobu prowadzenia projektu:
- w projekcie realizowanym etapami, dla którego estymacja kosztu i harmonogramu jest wiążąca dla bieżącej iteracji, konieczne jest doprecyzowanie tylko zakresu prac do tej iteracji (zauważone wątpliwości dotyczące innych prac warto odnotować, ale można pozostawić je jako nierozstrzygnięte sprawy otwarte),
- w projekcie, gdzie wiążąca jest estymacja kosztu fix-price i harmonogramu dla całości rozwiązania, specyfikacja nie może pozostawiać żadnych obszarów niejasnych/niezdefiniowanych, jeśli wpływają one na przyszłą pracochłonność zespołu.
Zweryfikowaną i potwierdzoną z właścicielem produktu specyfikację należy zachować w rejestrze dokumentacji projektowej jako wersję bazową dla śledzenia późniejszych zmian zakresu.
Przeglądy kodu i analiza statyczna
Przeglądy kodu programu to niezwykle skuteczna, chociaż stosunkowo rzadko praktykowana metoda zapewnienia jakości. Mogą być prowadzone na różną skalę, od dwuosobowej sesji, gdzie programista analizuje kod innej osoby, do sformalizowanych wieloosobowych spotkań). Poza poprawieniem jakości przeglądanego kodu korzystnym „efektem ubocznym” jest większa znajomość detali implementacji w całym zespole (pod kątem późniejszych zmian lub poprawek cudzego kodu) oraz rozwój kompetencji wszystkich uczestników przeglądu.
Przeglądy kodu są szczególnie skuteczne w wykrywaniu problemów wydajnościowych (np. odnajdywanie nieefektywnych fragmentów kodu, które nie wpływają na funkcjonalność, więc nie są wykrywane podczas większości testów) lub podatności na ataki (np. SQL injection).
Analiza kodu może być częściowo zautomatyzowana poprzez przegląd ostrzeżeń zgłaszanych przez środowisko programistyczne lub dodatkowe dedykowane narzędzia do analizy statycznej (np. Resharper, Lint).
Sesje przeglądów kodu i badania wyników analizy statycznej planuje kierownik projektu, w porozumieniu z programistą wiodącym. Powinny być one wykonane co najmniej dla elementów rozwiązania o kluczowym znaczeniu dla wydajności oraz bezpieczeństwa systemu (np. ekran logowania, kod kontroli uprawnień użytkownika).
Automatyczne testy jednostkowe
Automatyczne testy jednostkowe (oparte na frameworkach takich jak xUnit) zostały spopularyzowane przez metodyki agile, w szczególności Extreme Programming. Testy tego rodzaju polegają na opracowaniu dodatkowego kodu, który wywołuje poszczególne moduły systemu, z predefiniowanymi zestawami danych wejściowych, i porównuje uzyskane rezultaty z oczekiwanym zestawem wyników. Automatyczne testy jednostkowe są szczególnie przydatne podczas testów regresji, tzn. przy weryfikowaniu, czy zmienione lub dodane funkcje systemu nie wywołały efektów ubocznych, nie uszkodziły istniejących wcześniej rozwiązań.
Metodyka Rozwoju Oprogramowania BCC zakłada opcjonalne i ograniczone zastosowanie tego rodzaju testów. Jeśli aplikacja zawiera fragmenty ze złożonymi algorytmami przetwarzania danych, które mają kluczowe znaczenie dla jakości rozwiązania oraz pozostają względnie stałe w długim okresie (tzn. raz utworzone testy nadają się do wielokrotnego wykorzystania), to należy je zautomatyzować. Przykładem może być np. algorytm obliczania diety w delegacji na podstawie czasu trwania delegacji oraz liczby zapewnionych posiłków.
Aplikacje objęte niniejszą metodyką są zwykle związane z intensywnym przetwarzaniem danych w bazie danych. To operacje na poziomie bazy danych oraz interakcja pomiędzy wieloma elementami rozwiązania stanowi o poprawnym lub błędnym rezultacie (np. testujemy wprowadzenie nowego zamówienia przez klienta, a następnie weryfikujemy, czy wynik wykonania raportu sprzedaży uwzględnia prawidłowo to zamówienie). Tego rodzaju testy trudno zamodelować w ramach automatycznych testów jednostkowych, dlatego szerzej stosowane są automatyczne testy funkcjonalne.
Testy funkcjonalne
Testy funkcjonalne odpowiadają na pytanie, „czy można wykonać w systemie operację X?” lub „czy funkcja Y działa zgodnie z wymaganiami?”.
Scenariusze testów opierają się na koncepcji /specyfikacji wymagań systemu. Zazwyczaj koncepcja zawiera już wprost opis podstawowych scenariuszy, natomiast dla potrzeb testów jest potrzebne ich doprecyzowanie:
- lista konkretnych kroków, ze wskazaniem opcji menu, przycisków lub innych sposobów wykonania operacji w systemie,
- zestawy danych testowych, dla których przeprowadzamy test, i wskazanie oczekiwanych/prawidłowych rezultatów wykonania testu,
- wzorcowe profile użytkowników, skojarzone z odpowiednimi rolami, w celu weryfikacji poprawnego działania funkcji systemu w kontekście odpowiednich uprawnień użytkownika.
Prawidłowe scenariusze testów funkcjonalnych powinny obejmować wszystkie możliwe warianty przebiegu procesu w docelowym systemie, z uwzględnieniem różnych oczekiwanych rezultatów. Przykładowo scenariusz „złożenie nowego zamówienia przez klienta” powinien mieć warianty: „sprzedaż zakończona pomyślnie”, „brak poszukiwanego towaru”, „przekroczony limit kredytowy klienta” itp.
Z powodów opisanych powyżej przygotowanie scenariuszy testowych powinien wspierać doświadczony tester lub kierownik projektu. Samo wykonanie testów funkcjonalnych można delegować do różnych uczestników projektu, np. wybranej grupy użytkowników końcowych.
Automatyczne testy funkcjonalne
Automatyczne testy funkcjonalne symulują działanie systemu z poziomu standardowego interfejsu użytkownika. Są realizowane przy wsparciu dedykowanych narzędzi programistycznych (np. Selenium dla testów aplikacji webowych).
Ich przeznaczenie jest takie samo jak w przypadku testów „ręcznych”, lecz dzięki automatyzacji mogą być wykorzystane wielokrotnie, z minimalnym nakładem pracy. Z drugiej strony początkowe opracowanie testów automatycznych wymaga inwestycji czasu w przygotowanie uniwersalnego zestawu danych testowych i scenariuszy. Zmiany interfejsu użytkownika mogą też „uszkodzić” scenariusze testowe, np. jeśli zmieni się struktura menu, w którym nawiguje automatycznie test – wymagany jest więc nakład pracy na ich utrzymanie.
Z tych powodów automatyczne testy funkcjonalne opracowujemy w przypadku aplikacji, które mają względnie stabilny interfejs użytkownika, lecz są poddawane ciągłemu rozwojowi, tzn. testy będą wielokrotnie powtarzane. W takim przypadku nakład czasu na opracowanie testów i ich utrzymanie zwraca się w postaci bardzo szybkich i częstych testów regresji systemu, w dłuższym okresie.
Na schemacie poniżej/powyżej przedstawiono porównanie łącznego nakładu pracy na testy w czasie rozwoju i utrzymania systemu.

Porównanie łącznego nakładu pracy na testy w czasie rozwoju i utrzymania systemu
Testy bezpieczeństwa
Aplikacje przetwarzające dane o istotnym znaczeniu dla przedsiębiorstwa powinny być poddane testom bezpieczeństwa. Testy takie symulują różne próby naruszenia poufności, spójności lub dostępności aplikacji. Obejmują szereg technik, takich jak skanowanie systemu pod kątem znanych podatności bezpieczeństwa (np. luki w bazie danych lub serwerze WWW) oraz próby symulowanego ataku na system (testy penetracyjne).
W BCC (aktualnie All for One Poland) aplikacje są testowane przez dedykowany Zespół Bezpieczeństwa. Kierownik projektu uzgadnia terminy i szczegółowe podejście do przeprowadzenia testów z liderem tego zespołu.
Testy wydajności
Testy wydajności weryfikują czasy odpowiedzi i stabilność systemu przy określonym obciążeniu (liczba użytkowników i wykonywane przez nich działania).
Przeprowadzenie tego rodzaju testów jest dość pracochłonne i kosztowne. Wymaga opracowania narzędzi do symulowania obciążenia, mechanizmów pomiaru wydajności (np. statystyki na poziomie systemu operacyjnego), scenariuszy testowych i zestawu danych. Reprezentatywne dane testowe mają istotne znaczenie – np. sklep internetowy może działać sprawnie przy symulowanych powtórzeniach 1000 zamówień na minutę dla tego samego produktu (dane produktu, jego cena i dostępność będą stale w cache), ale spowolni działanie, jeśli będą to zamówienia 1000 różnych produktów.
W przypadku prostych aplikacji, wykorzystywanych przez niewielką grupę użytkowników i bez krytycznego znaczenia, ten rodzaj testów jest pomijany w Metodyce Rozwoju Oprogramowania BCC.
Do przygotowania testów wydajnościowych można wykorzystać istniejące scenariusze automatycznych testów funkcjonalnych – zmienione pod kątem wolumenu danych i liczby powtórzeń operacji.
Bez drogi na skróty
Od początku historii rozwoju oprogramowania – od kilkudziesięciu lat – kierownicy projektów, menedżerowie i klienci poszukują sposobu na zagwarantowanie wysokiej jakości projektów, realizowania prac w ramach budżetów i harmonogramów. Co kilka lat pojawia się nowa koncepcja (np. programowanie obiektowe), nowe języki programowania lub narzędzia (CASE, automatyzacja testów), ogłaszane przez ich zwolenników jako panaceum na wszystkie dotychczasowe problemy.
Wystarczy jednak sięgnąć do klasycznej książki Freda Brooksa „The Mythical Man-Month: Essays on Software Engineering” wydanej w 1975 roku (sic!), żeby przekonać się, że większość problemów związanych z tworzeniem skomplikowanych produktów programistycznych pozostaje niezmienna od niemal… 40 lat.
Z jednej strony nie widać więc na horyzoncie żadnej „drogi na skróty” (nowy język programowania, szybsze procesory itp.), która rozwiąże wszystkie problemy i dzięki której programy będzie się tworzyć „automatycznie”, bez wysiłku zespołów projektowych. Z drugiej strony optymistyczne jest to, że konsekwentne stosowanie kilku prostych zasad (chociaż „prosty” nie zawsze oznacza „łatwy”) pozwala uzyskiwać bardzo dobre rezultaty.
Podział dużego projektu na mniejsze elementy zakresu i iteracje pozwala weryfikować, czy dostarczane kolejno części rozwiązania są gotowe na czas i faktycznie działają zgodnie z oczekiwaniami. Zdroworozsądkowe podejście do dokumentacji – dokładna specyfikacja wymagań na początku projektu, dokumentacja techniczna tam, gdzie jest potrzebna i przydatna, a nie jako „sztuka dla sztuki”. Traktowanie zmian zakresu jako nieuchronnego elementu każdego projektu, a nie problemu. Wykorzystanie dobrych praktyk i narzędzi wspierających testowanie programów. Rolą Metodyki Rozwoju Oprogramowania jest właśnie edukowanie wszystkich uczestników projektu w odniesieniu do tych zasad i ich ciągłe przypominanie. Metodyka sama w sobie nie jest wystarczająca, ale jest konieczna do tego, żeby duże projekty programistyczne kończyły się w terminie, w budżecie i zgodnie z założonym zakresem.